|
|
浅析Hadoop两大核心组件的体系结构HDFS和MapReduce是Hadoop的两大核心。而整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持的,并且它会通过MapReduce来实现对分布式并行任务处理的程序支持。 HDFS和MapReduce是Hadoop的两大核心。而整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持的,并且它会通过MapReduce来实现对分布式并行任务处理的程序支持。 HDFS的体系结构 我们首先介绍HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个 DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。下图给出了HDFS的体系结构。
NameNode和DataNode都被设计成可以在普通商用计算机上运行。这些计算机通常运行的是GNU/Linux操作系统。HDFS采用 Java语言开发,因此任何支持Java的机器都可以部署NameNode和DataNode。一个典型的部署场景是集群中的一台机器运行一个 NameNode实例,其他机器分别运行一个DataNode实例。当然,并不排除一台机器运行多个DataNode实例的情况。集群中单一的 NameNode的设计则大大简化了系统的架构。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。 MapReduce的体系结构 接下来介绍MapReduce的体系结构,MapReduce是一种并行编程模式,这种模式使得软件开发者可以轻松地编写出分布式并行程序。在 Hadoop的体系结构中,MapReduce是一个简单易用的软件框架,基于它可以将任务分发到由上千台商用机器组成的集群上,并以一种高容错的方式并行处理大量的数据集,实现Hadoop的并行任务处理功能。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。 从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现了分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。 责编:毋小艺  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:畅享网文章著作权分属畅享网、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
最新专题 |

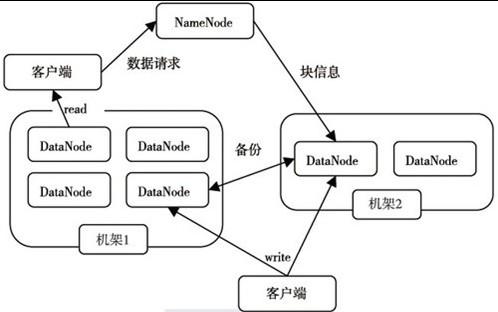 HDFS的体系结构图
HDFS的体系结构图
|
|

