|
|
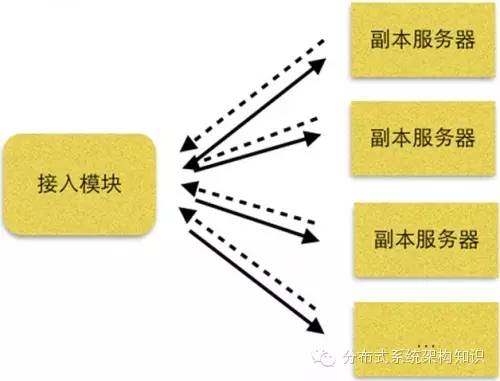
云存储的黑暗面:元数据保障(3)在开始讨论元数据保障的问题之前,我们先要牢牢记住一句话:“任何事物都会出错。”这个真理时时刻刻在发挥着惊人的作用。 本文关键字: 云存储 多副本模型 下面我们考查一个模型,暂且简单地称其为多副本模型。因为这种模型,就是利用众多元数据副本来保证可靠性和可用性的。与主从模型不同的是,多副本模型的各副本之间没有主次之分,所有的副本都处于相同的地位。因而,在向多副本模型写入元数据时,是同时向这些副本发起写入。而读取元数据时,也是向这些副本同时读(图1)。
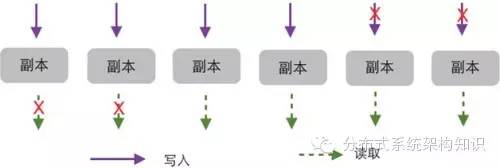
图1 多副本模型 多副本模型基于这样一个简单而直观的思路:单点会造成数据丢失,并引发可用性问题,那么就将数据同时写入多个服务器,以防单点的出现。不同于主从模型中,读写都针对一台主服务器,从服务器只是间接地参与可靠性和可用性的保障,多副本模型的每台服务器任何时刻都在直接发挥着保障作用。 由于每次读写都施加在所有的副本服务器上,任何时刻都有不止一份数据被保存下来,所以可靠性自然就解决了。同样,任何时刻都有不止一台服务器在运行,它们同时下线的可能性极小(暂且不考虑机房级别的整体故障),所以可用性也无需额外措施,便可以得到保障。正是因为每台副本服务器都是平等的,所以任何一台服务器下线都不会对整个集群的可用性和可靠性产生影响,系统仍然依照正常情况下的方式运行,别无二致。 这是多副本模型相对于主从模型的最大优势。无论哪台服务器下线,都不会引起系统运行状态的变化,运维人员可以从容地进行善后处理,没有服务下线的顾虑。而软硬件升级之类的日常维护工作,也不需要大动干戈地进行主从切换之类的危险操作,直接将服务器下线,进行更新便可。多副本模型的系统甚至可以容忍多台服务器下线,而不会造成系统运行的波动。具体的容忍限度取决于配置设定,关于这一点,后文有详细论述。 任何事物都有两面,既然多副本模型有它的优点,自然也有缺点。多副本的问题主要在一致性方面。由于我们允许副本服务器写入失败,再加上各种原因造成的数据退化,所以副本服务器之间的数据会不一样。当我们读取的时候以哪个为准呢? 这是一个值得考虑的问题。我们无法确定哪台副本服务器包含了完整新鲜的数据。实际上不可能有这样的服务器存在。因而我们也就无法从任何一台服务器中准确无误地读出所需的数据。唯一的办法就是同时读所有的副本服务器,综合所得的副本数据,以获得所需的信息。 如何综合副本数据呢?首先要确定基准。基准就是判定有效数据的标准,有时间基准和空间基准之分。时间基准用来处理元数据的先后覆盖,而空间基准用于处理副本之间的对应关系。在描述如何确定基准之前,先定下这样一个准则:对于一个数据对象的元数据,只有时间最近的那条是有效的。有了这样的准则,建立基准就容易了。我们可以为每一次元数据写入加上一个时间戳,并且确保一次元数据写入的各个副本拥有相同的时间戳,同时还需保证历次写入的元数据拥有不同的时间戳。只要能确保这两个条件,数据的基准就容易确立了。 具体的方法并不复杂,将读取到的副本数据放在一起比对,时间戳上最近的那些副本,就是所需要的。但并非所有的最大时间戳都是有效的。假设这样一种情况:一个元数据系统有5个副本,一次写入时,由于种种原因,只有两个副本写成功了。在读取这条元数据时,恰好那两台写成功的副本服务器下了线。这种情况下,这条元数据就无法读到了。其结果就是元数据不见了,直到那两台服务器重新上线。 为了避免这种情况的出现,我们需要引入一个规则,以确保无论怎样都能读到正确的数据。 这样的方法有不少,最常用的是WRN算法(图2)。这种算法比较简单,容易实现,使用也较广。算法的具体操作如下。
图2 WRN算法 假设有N个副本,当需要访问数据时,同时写或者读所有副本。如果写入时,有超过W个副本写成功,那么就认为这次写入是成功的,否则就算失败,向客户端反馈写入失败。读取时也一样,如果有超过R个副本读取成功,就认为这次读取是成功的,否则就算失败,或者数据不存在(具体是失败,还是不存在,需根据副本读取的结果加以判别)。W和R必须满足一个条件:W+R>N。只要满足这个条件,成功写和成功读的副本之间必然存在重叠,因而肯定可以读到至少一个有效的数据。 在具体使用中,WRN算法还有不少需要注意的细节。首先,具体读取各副本时,最简单的策略是取得该副本服务器中最新的那条元数据,然后依靠WRN算法整合这些所得的数据。这种做法在一般情况下可以正常工作,但在一些异常情况中会存在一致性问题。一种情况是一次写入时,没有满足成功写入W份副本的条件,那么这次写入算作失败。但其中写成功的副本因为时间戳更近,读取该副本时,会覆盖先前成功写入的那些副本。于是,最新写入失败的那个元数据读取时没有达到足够数量,而先前成功写入的元数据因为某些副本被这次失败的残留副本遮盖,也无法达到R数。于是便会出现无法取得有效元数据的情况。 这种情况属于低概率事件,但云存储系统经年累月不间断地运行,任何低概率的事件都会发生,而且必然发生。一旦发生,便会引发数据错乱的情况,影响用户的使用和服务的声誉。 针对这样的问题,有一些解决手段。最基本的手段是对于失败的写入操作,将各副本进行回滚。也就是将那些已成功写入的元数据条目副本删除。这种做法可以在一定程度上有效地降低问题发生的概率。但基于“任何东西都会出错”这样一个事实,我们认为回滚也会失败。回滚失败意味着依然会发生元数据无效的问题。 另外,还有一个解决方法:读取副本时不是只读最近的那一条元数据,而是读出几条。把各副本读到的元数据根据时间戳相互对位,还原出最原始的写入状态。在此基础上,剔除那些失败的写入数据,得到正确的数据。 还原写入历史的操作要求元数据在数据库中采用只增的方式,以便保留历史的条目。每次元数据的写访问,无论是新增还是覆盖,都是增加一条记录。与原有的元数据记录不同的是,这条记录携带新的时间戳。对于删除操作,则同样增加一条数据,并且设置记录中的“删除”标志,系统将根据此标志判断记录的删除操作。(只增也有助于避免事务,减少数据库锁的使用,对提升性能有所帮助。) 责编:何鹏  微信扫一扫实时了解行业动态 微信扫一扫实时了解行业动态 著作权声明:畅享网文章著作权分属畅享网、网友和合作伙伴,部分非原创文章作者信息可能有所缺失,如需补充或修改请与我们联系,工作人员会在1个工作日内配合处理。 |
最新专题 .mod_B_1{background:rgba(0, 0, 0, 0) url("http://www.vsharing.com/bacohome/2015/cio.. 专家专栏 |












|
|

